
This page provides a publicly-available information selected projects developed by VIStology. Click here to see a list of selected OWL ontoogies developed by our team.
Selected R&D Projects
DeVISor
Technology developed under DARPA STTR Topic: “A Flexible and Extensible Solution to Incorporating New RF Devices and Capabilities into EWI ISR Networks”
Introduction
In order to realize the vision of “mosaic warfare”, autonomous EW/ISR networks will require rapid insertion of new types of Applications and new types of RF devices with new capabilities. Currently, such insertions require recoding of the middleware that matches applications requests with currently available devices capable of executing these requests. To lower the time required for such dynamic insertion, while also lowering the cost, VIStology is developing DeVISor – a semantic matcher that can run on the network as a service and infer which of the devices are capable of satisfying a given request based on the knowledge provided by the device at registration. Once a match is found, the request is forwarded to the device, which then performs the service and returns the result back to the application.
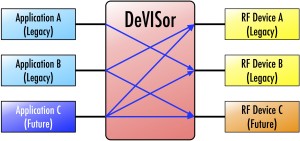
The minimal requirements to achieve this capability are:
➢ Applications express requests for services in a common language (ontology)
➢ Applications implement JSON-RPC protocol to send their requests to DeVISor and receive results
➢ Devices implement a single JSON-RPC method for registration with DeVISor
➢ Devices map their radio functions to the common language (ontology)
➢ Devices provide access to radio functions via JSON-RPC interface.
Benefits
➢ Mission Advantages (Flexibility and Robustness): Can (automatically) infer that one of the nearby radios is capable of performing a given application request, e.g., to sense spectrum in a specific location/band/time – thus accomplishing tasks that would not be possible otherwise.
➢ Flexibility to the Mission: Ability to (re)assign (on the flight) computational and sensing tasks to devices that move into a specific location, e.g., teams coming together.
➢ Future-proofing: Inclusion of new RF Devices and Applications without recompiling network or device software.
➢ Financial Benefit: Adding new Application types and Device Types to an ESM/ISR network is two orders of magnitude less expensive than modifying the matching code to accommodate new Applications/Devices and then recompiling and re-deploying the updated software.
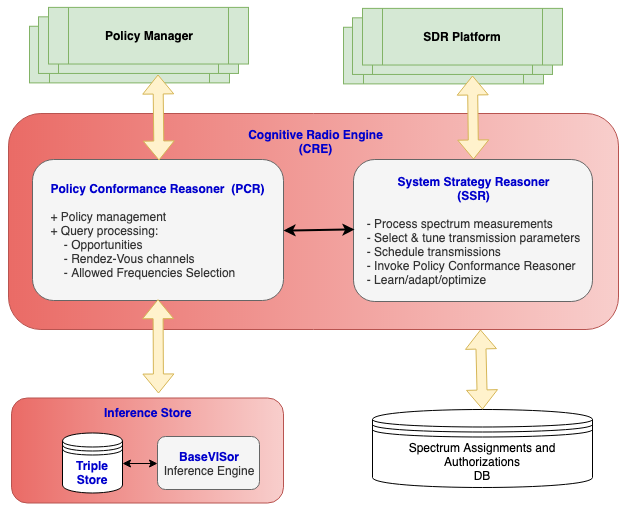
Dynamic Spectrum Access (DSA)
VIStology lead and supported several efforts related to DSA:
➢ Developed software for DSA policy management and execution
➢ Implemented algorithms for deriving transmission opportunities and rendezvous channels based on policy rules
➢ Drove the effort of developing the Cognitive Radio Ontology (CRO) at the Wireless Innovation Forum
➢ Developed a middleware and a language (SpectralSPARQL) for exchange of spectral knowledge
![]()
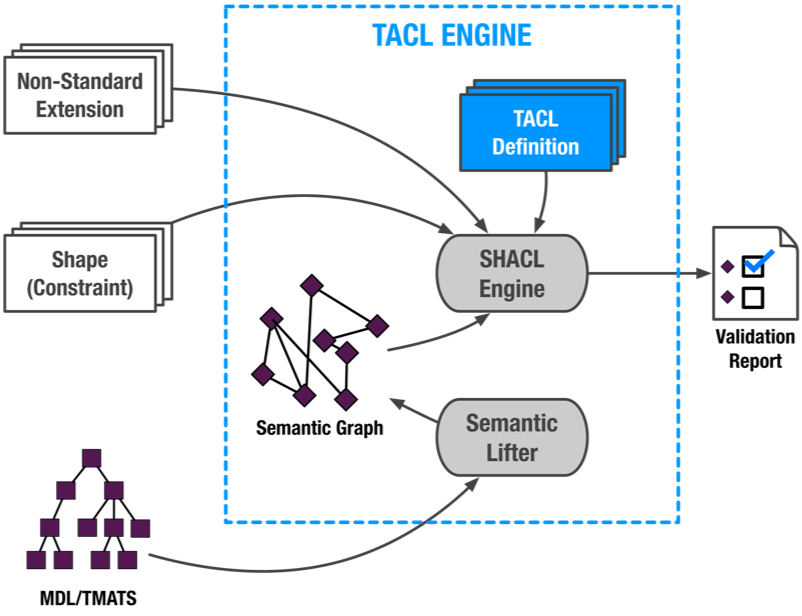
Despite their numerous benefits, T&E XML-based languages like MDL and TMATS do not address all of the challenges related to building multi-vendor T&E systems in a truly vendor-agnostic workflow. In particular, they cannot harness the complexity of constraints that may pertain to vendors’ hardware or to express system-level constraints that span across entire networks of devices and differ across different users. The T&E community has recognized the fact that MDL and TMATS XML are not sufficient to address this problem alone, and that there is a need for a separate, constraints language. Constraints written in such a language can be validated by a third party validation engine, without relying on any particular vendor’s software.
To address this challenge, we developed a concept of TACL — a proposal for a standard language for formulating constraints on configurations represented in MDL and TMATS. TACL is a backward-compatible extension of the W3C Shape Constraints Language (SHACL). SHACL treats constraints as first-class citizens and facilitates building high-level domain-specific expressions resulting in constraints that closely resemble the user’s intent and are not boggled with low-level data structures. A reference implementation of a TACL engine, named xVISor, has been developed and integrated with the iNET System Manager. The resulting system is capable of fully configuring cross-vendor systems without relying on any vendor-provided software.
![]()
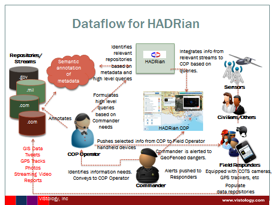
HADRian is next-generation Common Operational Picture software for HA/DR ops.
HADRian enables an Incident Commander to formulate a query and
- Find
- Filter
- Geocode
- Display and
- Dispatch
the relevant context information that he or she needs to make the best decisions about the situation on the basis of semantic annotation of information repositories.
Repositories or information streams that are integrated into the HADRian COP can include text reports, social media, photos, streaming or static video, traffic cameras, GPS tracks, chemical plumes, 3D building models (SketchUp) and other sources of information as they are identified.
HADRian is a field-tested Phase II SBIR project.
Benefits
Unlike current COPs, HADRian allows the user to do more than just toggle pre-specified information streams on and off in a geospatial display.
Incident commanders do not need to know where relevant information is stored or how it is formatted. HADRian infers the repositories that are relevant to an information need and extracts the needed information.
New information streams or repositories can be easily integrated as they are found. Selected information from the COP can be dispatched to field operator smartphones. Geofencing is enabled.
HADRian integrates, aggregates and summarizes information streams to answer standing queries such as Essential Elements of Information (EEIs) for HA/DR ops.
VIStology PolVISor: Security Policy Reconciliation
![]() VIStology PolVISor uses semantic reasoning to automatically reconcile and interpret security policies across multiple distributed security domains. Client and server policies are reconciled into a Security Policy Instance that enables application session, resource access and information exchange. PolVISor’s declarative ontology and rule-based reasoning provides a modular interface to procedural security mechanisms.
VIStology PolVISor uses semantic reasoning to automatically reconcile and interpret security policies across multiple distributed security domains. Client and server policies are reconciled into a Security Policy Instance that enables application session, resource access and information exchange. PolVISor’s declarative ontology and rule-based reasoning provides a modular interface to procedural security mechanisms.
PolVISor Benefits
• Policy authoring in simplified English (SBVR Structured English)
• Expressive formal language for representing policies
• Simplified integration of new domains
• Simplified policy management across domains
• Manual policy reconciliation replaced by automatic policy reconciliation
PolVISor Overview
When a client or server requests access to another server’s applications, resources or clients, PolVISor intercedes and requests the client’s and server’s security policies. The requirements of the security policies are analyzed and reconciled to ensure that all are met before application sessions, access to resources, or information exchange is allowed.
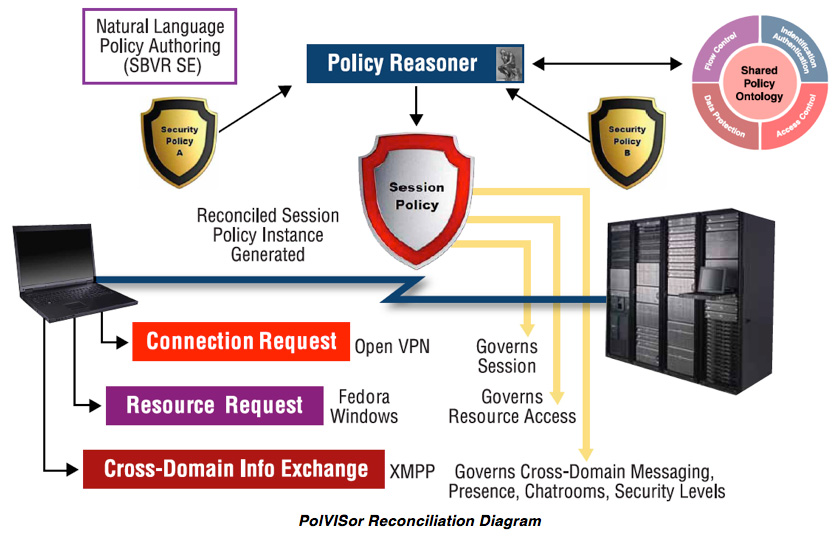
PolVISor Technology
PolVISor employs ontology and rule-based reasoning implemented in OWL 2 RL. Security policy rules are authored in a simplified English called SBVR Structured English, an OMG Standard. Policies are then translated into RDF or OWL and RIF statements that can be processed using the PolVISor Reasoner to reconcile client/server security policy with another server’s security policies within the distributed security domains. Policies are expressed in a vocabulary drawn from a shared or merged ontology.
Provisioning Policies
When a client requests a session with a server, the server has a set of security measures that must be met by the client before allowing the connection. This set comprises the provisioning requirements specified by the responder’s policy. The client may also have its own set of security requirements; these are the requester’s provisioning requirements. Reconciliation yields a concrete instance that satisfies both policies.
Authorization Policies
Policies can also specify access authorization restrictions, including rights to read or modify resources such as documents or databases. If the requester and responder have different authorization policies, the policies need to be reconciled. Common access authorization restrictions concern authentication of the client’s identity and access privileges via digital certificates, digital signatures or passwords.
Information Exchange Policies
In an XMPP (instant message/chat) framework, two servers may impose different policies on who may directly communicate (message), see who is online (presence) or exchange information in shared spaces (group chat, exchange files, publish/subscribe to data streams). Policies imposed by the various servers are reconciled and a solution that satisfies every server’s policies is implemented, if such a reconciliation policy exists.
For example, financial services regulations regulate communications between analysts and traders (FINRA 2711) and between financial representatives and customers (FINRA 2310). As such, if a company wishes to allow its employees and customers to interact via XMPP, these communications must be monitored for compliance with the necessary regulations. Additionally, the compliance of employee’s use of Twitter and other social media tools can be enforced via an XMPP interface to those services.
Relevance Reasoning
VIStology’s Relevance Reasoning supports a form of meta-querying of data. It provides a means to filter and identify data sources relevant to a user’s needs using semantic annotations. Relevance reasoning does not examine the contents of a data source, only its semantic annotations (i.e., semantic metadata). In doing so it relieves a query processor of additional processing load and can minimize the need for extensive date indexing.
VIStology’s Relevance Reasoning has been used in several Humanitarian Assistance/Disaster Relief exercises.
Meta/High Level Queries
To facilitate VIStology’s Relevance Reasoning a user’s Meta or High Level Query (HLQ) is used as an entry point. An HLQ is a simplified representation of possible areas or scopes of interest to a user expressed in terms of an underlying ontology. It’s not a query in any particular query language, such as SQL or SPARQL, but rather a set of scopes of interest to a user. These ‘scopes’ are represented in an underlying OWL ontology and may be expressed with complex OWL class expressions. The most common ‘scopes’ for Relevance Reasoning and of a High Level Query include:
➢ Region Scope – a geo-spatial region
➢ Time Scope – a temporal range
➢ Thing Scope – the kind of thing being queried for: e.g., a magazine.
➢ Topic Scope – specifies what the ‘things’ of the Thing Scope are about: e.g., magazines about Sports.
➢ Source Scope – specifies a class of sources that all the things satisfying the query must have been produced by.
The collection of ‘scopes’ can be extended for particular domains or uses.
An HLQ may also include specific parameter values. For example, a query for businesses listed in Yelp (yelp.com) may have a parameter for ZIP code filled in by a user with the ZIP code corresponding to the area selected in the Region Scope of the HLQ.
Data Sources
For Relevance Reasoning a data source is any collection of information defined either extensionally (i.e., a pre-specified collection of things) or intensionally (i.e., items that satisfy certain criteria). For example, a collection of photos in an individual user’s Flickr online photo album represents a collection defined extensionally: the collection was defined by the user’s selection of photos for that album. A Flickr query for photos taken in Yosemite Park on a particular date, however, can be considered a data source that is determined intensionally: The set of photos that meet this criterion is not necessarily known in advance. Each data source needs a URL associated with it to enable retrieval (extensional) or querying (intensional) of the data.
In order to determine relevant data sources each is semantically annotated with the ‘scopes’ described above: Thing, Topic, Region, Time and Source Scope. As example, a data source of tweets about traffic accidents in Paso Robles, CA, created during 2012 from the Paso Robles (CA) Police Department could be annotated with the following scopes:
Thing Scope: StatusUpdate
Topic Scope: TrafficAccident
Region Scope: Paso Robles, CA
Time Scope: 2012
Source Scope: Paso Robles Police Department
A data source is inferred to be relevant to an HLQ if (but not only if) its scopes overlap with the Thing, Topic, Region, Time, and Source scopes of the HLQ. For a scope specified in terms of a class, then a subclass or superclass overlaps with it. Regional and temporal overlaps are defined via overlapping areas and intervals, respectively. A Topic Scope can be defined to be relevant in several ways, for instance equality or equivalence of the classes or with any coreferential term (designating an instance of a class).
Reasoning
Relevance Reasoning is processed through VIStology’s BaseVISor a customizable, forward-chaining OWL 2 RL inference engine. It provides inference rules for the OWL 2 RL language profile and can be extended with custom rules.
BaseVISor has the unique feature of being able to use rules augmented with user-supplied procedural attachments to perform custom functions in addition to default functionality for mathematical functions, string operations and the like.
Results Reasoning
When additional refinement of Relevance Reasoning is needed, Results Reasoning can be applied subsequently to the data from a (relevant) data source. This can provide an additional level of granularity to meet a user’s needs. Results Reasoning is a capability that can be used to aggregate and summarize results for high level information needs on the basis of underlying large datasets, where simply representing every element of a dataset as a “dot on a map” would overwhelm a user.
ConceptMaps
VIStology’s ConceptMaps is a tool (under development) that processes large RDF datasets and provides situational awareness using semantic graph visualizations of facts relevant to a query. Irrelevant facts are filtered out; remaining facts are abstracted and represented in a simpler and more comprehensible form. The tool supports an analyst in the following tasks:
➢ Describing a situation to identify in the graph
➢ Filtering irrelevant facts
➢ Providing visualization of the filtered information in the form of an interactive graph
➢ Graphically manipulating the graph for easier comprehension
➢ Automatically updating/learning transformation rules based on feedback
ConceptMaps is based on Situation Theory and Semantic Web technologies. The notions of “focus question” and “context” are integral parts of the notion of “situation”. VIStology has developed a Situation Theory Ontology (STO) that is based on Barwise and Perry Situation Theory. In STO, Situation is a central concept and one of the functions that it fulfills is the representation of context. STO also includes the notion of relevance and allows the reasoner to infer which concepts and relations are relevant to a given situation. SPARQL engines do not provide this capability, they could only answer whether a situation of specific type exists or not.
Benefits
➢ Increased analyst’s productivity
➢ The analysts need to formulate questions and use ConceptMaps to produce significantly smaller graphs that are focused on their particular needs. The tool produces easy to comprehend graphs that allow the analyst to quickly make decisions and discover the stories hidden in the large graphs.
➢ Improved quality of analyst products
➢ ConceptMaps produces graphs that are easier to comprehend than the original RDF data, resulting in fewer false alarms and improved detection of relevant events. The tool does not just answer a query, but also uses automatic inference to include all relevant facts.
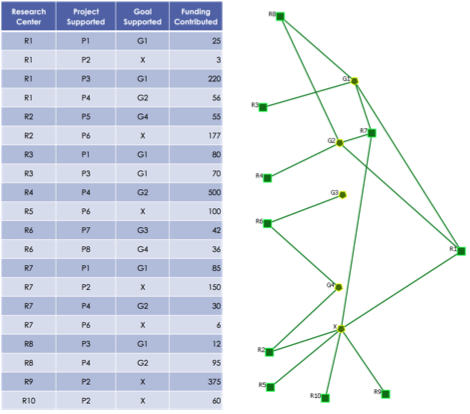
Example
To illustrate how the ConceptMaps can be used to support decision-making, a small, fictional dataset posted by West Point Network Science Center is used as an example . Figure 2 shows the dataset with ten research centers, eight projects, four agency goals and the funding each project received from particular center. The goal “X” is not aligned with the agency’s goals. Assume that the task is to identify where the funding should be cut. One way to analyze the data in the first place would be to identify centers that do not support goals aligned with the agency.
The tabular data can be easily converted into RDF using one of many off-the-shelf tools. Formulating a specific SPARQL query could identify information about the relationships between the research centers and the goals they support. The visualization next to the table shows such a graph. Although the graph is clearly easier to comprehend than the table, it is not readily obvious which centers exclusively support goals that are aligned with the agency and which centers support goals not aligned with the agency only. The analyst has to visually inspect the graph, which could be very challenging as the number of nodes increases and the associations between the nodes are more complex.
Figure 3 shows the same dataset processed by ConceptMaps. Each graph shown in the tool corresponds to a different analyst query, and effectively to a different situation, identified by the tool. The graphs include the centers, but also the related projects and goals, because they are inferred as relevant to the analyst’s query. Nodes are colored differently depending on the concepts they represent.
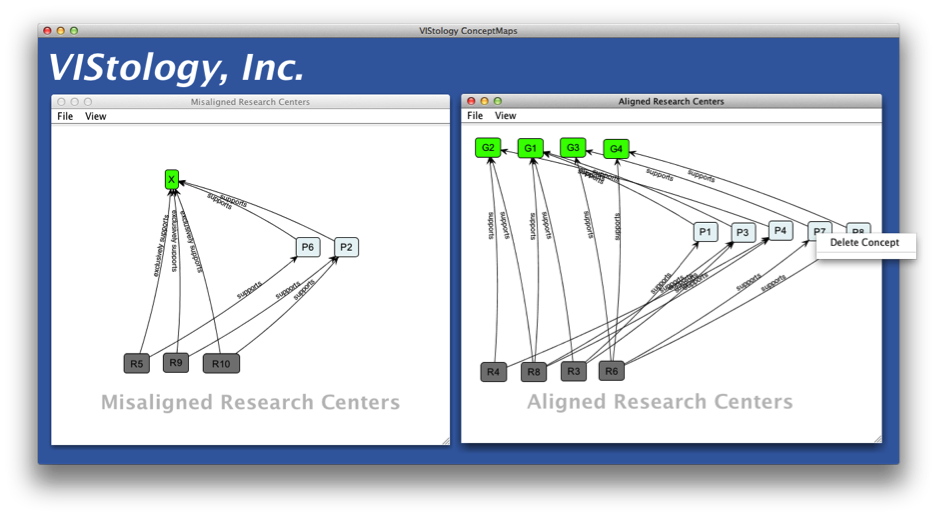
The tool sports an interactive interface, allowing the user to modify the automatically produced and laid out maps. Each concept and edge can be removed, which provides feedback to the tool. The tool uses the user feedback to update and/or learn transformation rules, so that next time the data is processed, the result is better aligned with user needs.
ReqVISor
System requirements elicitation is a time consuming process with an extremely high penalty for errors. Mistakes made in the requirements phase will cost 50 times more to fix while they are uncovered in the production phase as compared to fixing them in the requirements phase. VIStology and Northeastern University developed an approach for supporting the requirements elicitation phase. ReqVISor is a tool that decreases the time required to collect the true needs of the stakeholders, while increasing the output quality and decreasing the number of repeated iterations during the stakeholder needs elicitation process. ReqVISor improves the elicitation process by automatically identifying statements that potentially violate need statements acceptability criteria (policies), suggesting clarification and/or expansion, and maintaining a requirements database for reuse and learning.
A prototype of ReqVISor was developed under MDA Phase I STTR project. The main objective of this project was to develop a tool that can:
- Analyze requirements represented in text
- Extract information from text and represents it in a formal language with computer processable semantics
- Analyze the formal representation of specifications
- Store the formal representations for future extraction and comparison
- Guide the systems engineer during the requirements formalization and analysis
Benefits
- Increased quality of the requirements
- Decreased number of iterations during the requirements elicitation
SALIENCE
An intelligence analyst’s job is to monitor streams of incoming reports and sensor data for information relevant to a situation, detect the salient information, answer the commander’s priority intelligence requirements (PIRs) and distill the salient information into a concise estimate of what is currently going on, what is most likely to happen next, and what is the most dangerous course of events that could happen next. How can the most salient information be identified?
Here we leverage intelligence artifacts to model an analyst’s interests. Entities are important and should be called out in new information to the extent that they have recently appeared in intelligence artifacts and intelligence requests. As such, our Salience system is like a Google Priority Mailbox for intelligence analysts. It flags incoming information as important to the extent that it includes information about things that have recently been included in intelligence reports or requests, based on a salience metric we have developed that combines information retrieval, ontology-based metrics and social network metrics.
Benefits
- This technology proactively prioritizes information as it comes into the system, alerting analysts to what is expected to be most relevant to their work, making the analyst more efficient and more effective.
- In Phase I, we demonstrated a 200% increase in identifying important reports over a baseline by leveraging an ontology based on intelligence products.
- While aimed at intelligence analysts, this technology is applicable in commercial settings as well, in any field that requires situation awareness via the compilation and distillation of information from outside of the enterprise.
SWAE
STTR Topic Number: OSD09-SP6. Title: Semantic Wiki for Page Alerting
Period: February 4, 2010 – August 3, 2010 (Phase I)
SWAE (Semantic Wiki Alerting Environment) provides a semantic wiki-based environment for automatically analyzing large amounts of changing information about collections of people, groups, places and events, alerting operators to critical changes and events relative to an evolving semantic model of the problem space.
In the Global War on Terror (GWOT) large amounts of data must be effectively analyzed in a timely manner in order to provide an accurate and up-to-date understanding of current and potential threats. Key to understanding these threats is the identification and characterization of the various entities that they involve – relevant individuals, groups, locations and events along with their corresponding interrelationships (e.g., which individuals belong to which groups, which groups are involved in which events that are occurring at which locations). Due to the vast quantity and wide disparity of the data available to the analyst it is highly desirable to be able to describe entities and relationships found in the data in a consistent and formal manner that will lend itself to automated computer processing.
In Phase I the problem domain of street gangs was selected owing to their analogous relationship to terrorist or insurgency organizations and the relative abundance of freely available online sources of ever changing information from sources such as online news, government press releases, blogs, Twitter, Flickr, YouTube, MySpace, FaceBook, etc. The W3C Web Ontology Language OWL was used to define a “vocabulary of discourse” comprised of relevant classes, properties and relationships. A web-based knowledge management wiki was used to collaboratively capture and manage complex interrelated knowledge in the form of free text, images, audio, video, etc. all accessible through a web server.
Benefits
- This technology would allow the analyst to set up “standing queries” for a specific type of event of interest. SWAE would then monitor a stream of information and alert the analyst when an event of the type specified by the query occurs.
- The primary benefit of this approach would be an improvement in the amount of information processed by the analyst, higher detection rate of events of interest and lower rate of false alarms.
Selected ontologies developed by VIStology
Data and Workflow Provenance Ontology
Download: Provenance Ontology (.owl)
Distributed Semantically-Integrated Information Services (DiSIS)
Download: DiSIS (.owl)
Joint C3 Information Exchange Data Model (JC3IEDM)
JC3IEDM is a Nato data model standard. This is an automated translation of the JC3IEDM into OWL. It is based on formal ERWin Data Model Definition, comprises 271 etities, 372 relationships between entities, 753 entity attributes and over 10,000 value codes.
Download: JC3IEDM 3.0 (.owl), JC3IEDM 3.1a (.owl)
Situational Awareness Ontology (SAW-Core)
Download: SAWCore (.owl), SAWCoreLite (.owl)
Security Policy Ontology (SecPol)
Download: Deontic Ontology (.owl), Upper SecPol Ontology (.owl), XMPP Ontology (.owl)
STANAG 2022 Ontology
Download: STANAG 2022 (.owl)
Situation Theory Ontology (STO)
Download: STO (.owl)
Street Gang Ontology (SWAE)
Download: Gangs Ontology (.owl)
Structured Threat Information eXpression (STIX)
Download: STIX (.owl), CAPEC (.owl), Cybox (.owl), Cybox Common (.owl), Data Marking (.owl), Kill Chain (.owl), MAEC (.owl)
Other Projects
ConsVISor
ConsVISor is a rule-based system for checking consistency of ontologies serialized in RDF, OWL1 or DAML. In addition to identifying logical contradictions in an ontology, ConsVISor can warn the ontologist about elements that, while not necessarily inconsistent, may not be what was intended.
SKF – Spectrum Knowledge Framework
Annotation and exchange of spectrum information by the Electronic Warfare systems.
DiSIS
Permit ready access to large amounts of disparate information distributed across heterogeneous data sources using semantically rich queries without users needing to know where the requisite information resides, what format it is represented in or what technology is required for its access
MOCOP: Functional Allocation Trades Between Hardware and Software
SCOPE: Secure Cyber Optimal Path Evaluation/Generation
PIRAT: Tools to Support Priority Intelligence Requirement Answering and Situation Development
SIXA: Development of Battlespace Information Flow and Content Methodology